Le contexte
Profilia est un projet personnel que j’ai lancé pour éprouver une hypothèse simple à formuler, beaucoup plus difficile à exécuter : est-ce qu’en empilant dix tests de personnalité reconnus, deux langues, et plusieurs dizaines d’articles de fond par thème, on peut construire un actif SEO qui se capitalise tout seul, mois après mois ?
La réponse, pour l’instant, est positive et la courbe de trafic continue de monter. L’objectif maintenant est de prolonger cette dynamique sans sacrifier la qualité du contenu, ni l’expérience des tests.
Le défi
Plusieurs contraintes à tenir en même temps :
- Bilinguisme complet FR et EN sur les tests, les profils, le blog et l’interface, sans duplication de contenu ni pénalité de référencement (balises hreflang, adresses localisées).
- Volume de contenu maîtrisé : près de 200 articles entre les deux langues, rédigés avec un véritable angle éditorial, pas du texte automatisé à faible valeur.
- Parcours de quiz fluide : dix tests de 15 à 30 questions chacun, chargement rapide, reprise possible même sans création de compte.
- Profil ADN synthétique : croiser les résultats de plusieurs tests pour générer un méta-profil qui donne envie de finir les dix.
- Module d’analyses maison pour piloter : quel test convertit, quel article amène le trafic, à quelle étape les utilisateurs décrochent.
Ce que j’ai fait
Produit
- Conception des dix tests : DISC, RIASEC, Jung, Tempéraments, Chronotype, VARK, Langages de l’amour, Quatre Tendances, Styles de leadership, Animal totem.
- Système de profils par test (de 4 à 16 profils selon le test), chacun avec sa fiche dédiée, son image de partage générée dynamiquement et son maillage vers les articles pertinents.
- ADN personnalité : méta-profil qui se débloque à partir de trois tests complétés et s’enrichit à chaque nouveau test.
- Mode anonyme par défaut pour abaisser la barrière à l’entrée, compte optionnel avec authentification par lien envoyé par email quand l’utilisateur souhaite conserver ses résultats.
Tech
- Pile technique Laravel 13, Inertia.js et React 19, base PostgreSQL, rendu côté serveur via un conteneur Node dédié pour que chaque page de résultat ou d’article arrive indexable, et non reconstruite côté navigateur.
- Tailwind v4 avec
@themecomme source de vérité pour les tokens de design, composants Radix pour les motifs d’interface complexes. - Pipeline de contenu bilingue : séparation stricte entre configurations PHP (métadonnées et profils envoyés via Inertia) et TypeScript (questions et interface, chargés à la demande côté client).
- Intégration continue GitHub Actions : Pint, ESLint, Prettier, TypeScript strict, Pest (PHP) et Vitest (JavaScript) exécutés sur chaque pull request.
- Sentry côté serveur et côté navigateur pour détecter les régressions en production avant qu’elles ne remontent dans les métriques business.
- Dockerfile multi-étapes pour la production, une seule commande
make deployqui enchaîne récupération du code, sauvegarde de la base, construction des assets, redémarrage, vérification de santé et purge Cloudflare.
Growth & SEO
- Images de partage générées automatiquement pour les quelque 200 articles et les profils de quiz, produites par une seule commande
make og-images. - Maillage interne dense entre blog, tests et profils, pensé autour des intentions de recherche et non des catégories internes.
- Core Web Vitals au vert sur toutes les pages, grâce au rendu côté serveur, au HTML statique préchargé et à un sous-ensemble de polices réduit au strict nécessaire.
- Tableau de bord graphique (Recharts) pour suivre l’entonnoir : trafic organique, démarrage d’un test, complétion, puis création de compte.
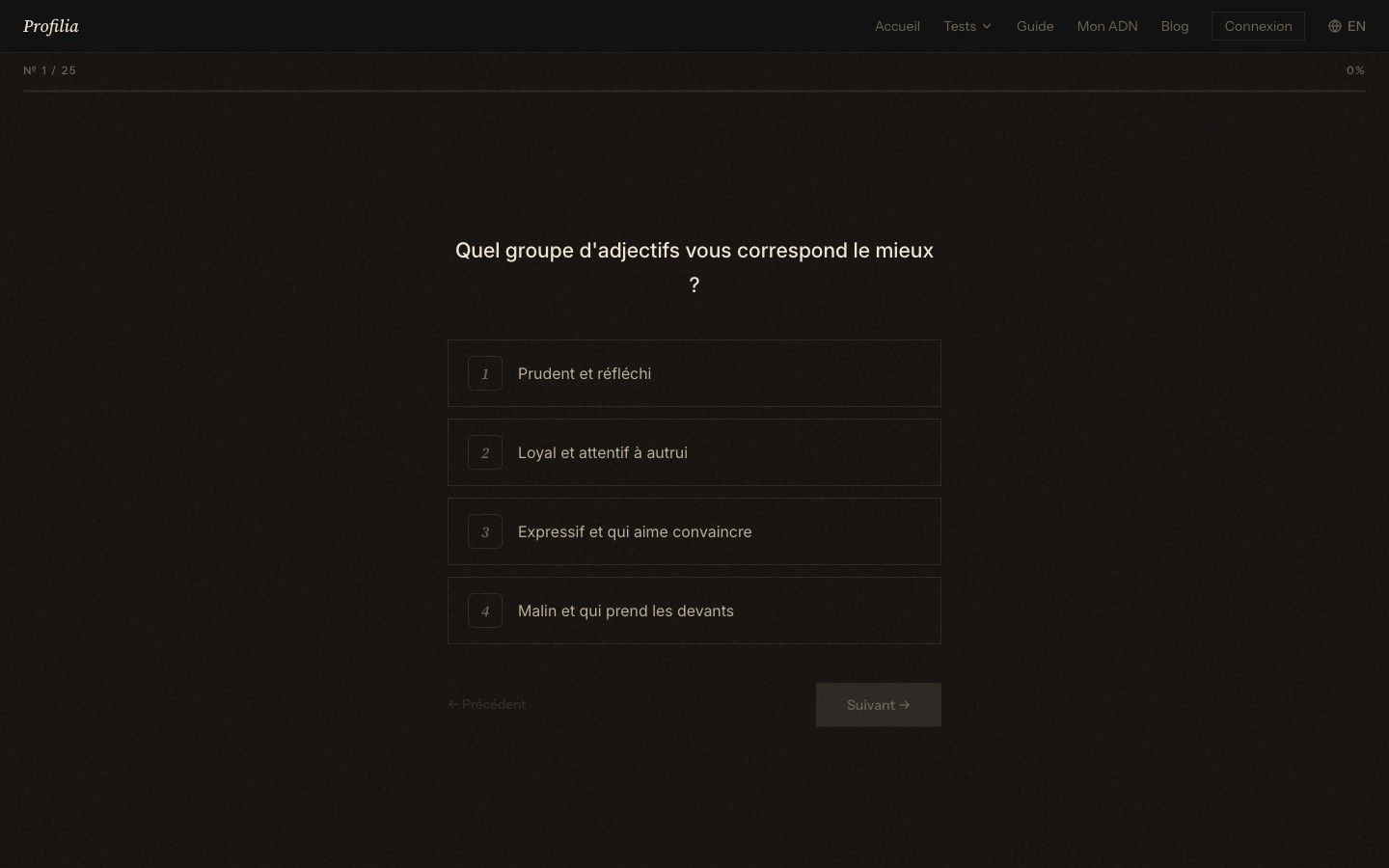
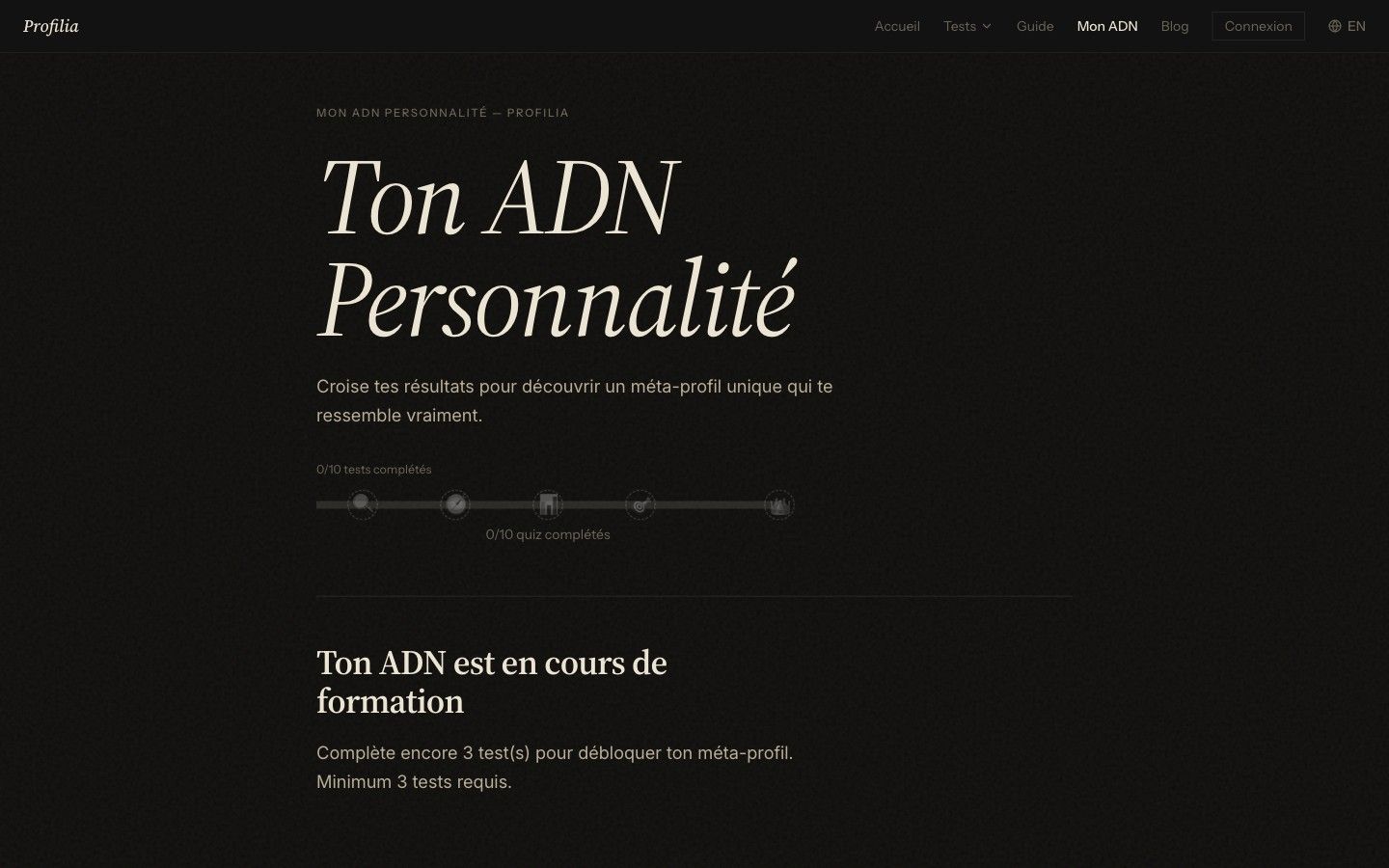
Stack et choix techniques
J’ai hésité à partir sur Next.js, puis j’ai choisi Laravel et Inertia pour trois raisons :
- Je travaille avec Laravel depuis longtemps, je voulais itérer rapidement sur l’administration, les files d’attente et les migrations, pas réinventer une API.
- Inertia offre l’expérience d’une application React côté client sans avoir à construire une API REST dédiée : un seul projet, des types partagés, pas de requêtes redondantes.
- Le rendu côté serveur via un conteneur Node séparé conserve le contrôle total du référencement, tout en gardant la dynamique d’une application moderne.
PostgreSQL plutôt que MySQL pour les requêtes analytiques de l’administration (regroupements sur les complétions, séries temporelles). Sentry en front et en back parce qu’un projet personnel sans supervision devient rapidement un projet personnel abandonné.
Résultats
Phase d’amorce assumée : les volumes bruts restent modestes, mais les signaux qualitatifs sont nets. Les personnes qui commencent un test le terminent (67 %, au-dessus du standard de l’industrie qui se situe entre 30 et 50 %), elles passent en moyenne plus de 5 minutes sur le site (engagement réel, pas de rebond instantané), et la dynamique mensuelle est franchement à la hausse. DISC porte le trafic avec 63 % de conversion sur les démarrages de test, la première source d’acquisition est Google en recherche organique, et le socle SEO est en place pour absorber le prochain palier de croissance.
Si la stratégie SEO à grande échelle vous intéresse et que vous voulez en discuter, écrivez-moi.